Desperate for Data Science skills
LinkedIn published its Workforce Report for August 2018 in August, 2018. The major subject of the report was about Data Scientists. Demand for data scientists is off the charts. In 2015, there was a national surplus of people with data science skills in the U.S. But in 2018, 3 years later, the picture changed considerably: shortage of data science skills exists in almost every large U.S. city. Nationally, U.S has shortage of 151,717 people with data science skills. As more industries rely on data to make decisions, data science has become increasingly important across all industries, not just tech and finance. In that sense, it’s a good proxy for how today’s cutting-edge skills like AI & Machine learning may spread to other industries and geographies in the future.
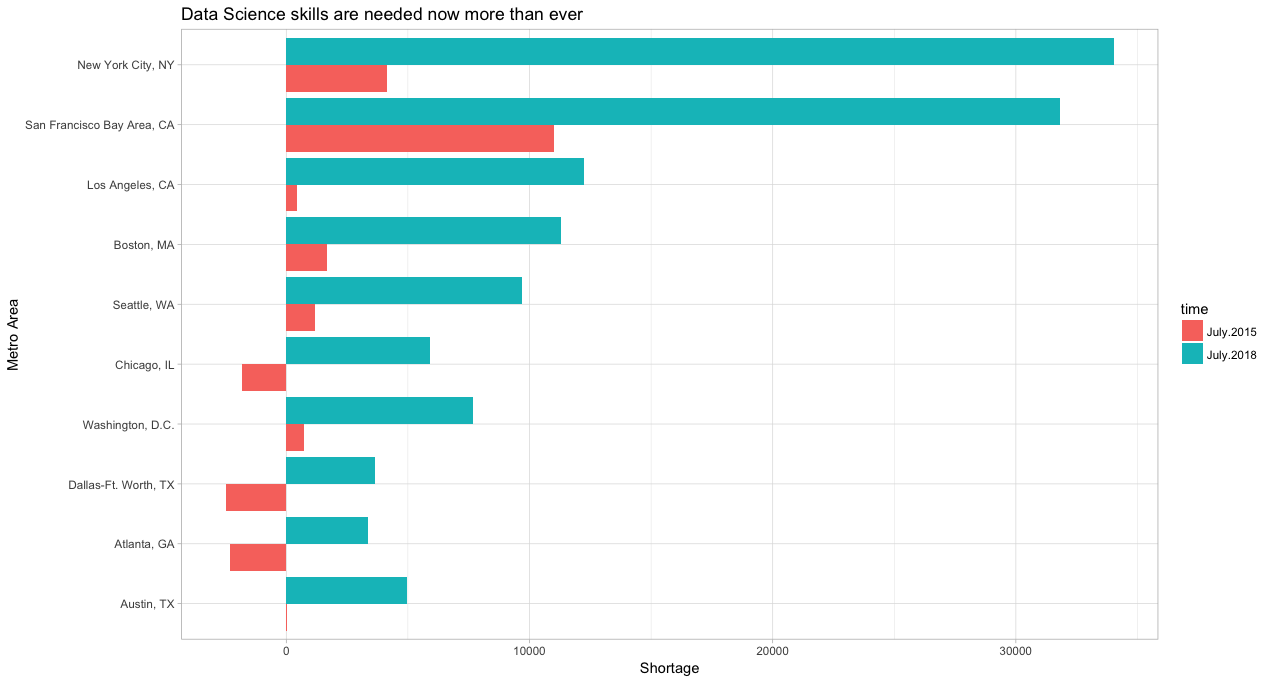
The above plot ranks U.S. metro areas by the intensification of data science skill gap between July 2015 and July 2018.
Another interesting fact is that the shortage of data science skills is growing faster than the national shortage of software development skills (which includes programming languages, like C++ and Java). There was shortage of 212,838 people with software development skills in 2018. But 3 years ago, software development skills were already in shortage nationally—so the “intensification” of the shortage for data science skills is actually larger than that for software development.
Solution
We should attack the problem from 2 sides:
- Train more data scientists
- Make them as efficient as possible
Training more data scientists
Fortunately, the are some massive open online courses (MOOCs) of high quality, which train data scientists and machine learning engineers at massive scale. MOOCs are also perfect for retraining current data scientists to teach them recent advancements in the field. Here, I will list 2 online course series, which are well respected and highly rated by the community.
“Deep Learning Specialization” by Andrew Ng and deeplearning.ai . Specialization contains series of courses, which start from introduction to neural networks and deep learning. Two last courses teach convolutional neural networks and sequence models. Coding exercises use python, tensorflow and keras.
“Deep Learning For Coders” course series by Jeremy Howard and fast.ai. The series includes “Practical Deep Learning For Coders” and “Cutting Edge Deep Learning For Coders”. Coding exercises use pytorch and fastai library.
The rest you can find here and here.
Making them as efficient as possible
How can we make data scientists as efficient as possible on their job? We need to have 2 things for that: fast and reliable infrastructure and efficient tools.
Reliable infrastructure
Since data science field is relatively new (than, let’s say, software development), most of the companies haven’t figured out yet how to build a reliable data science infrastructure (except top tech giants like google, microsoft, amazon, etc). Data scientists suffer a lot when they don’t have a reliable infrastructure. Then they spend most of their time talking to IT support of their company, waiting to get the result of their running script, because their computer is too slow, or wrestling with their development environment to solve some bug in some random library.
You can solve this problem in 2 ways: either by building the required infrastructure in your company or by paying for some external cloud solution. Perhaps big enterprises will prefer building everything in-house, while it’s much better idea for small and medium sized companies to rent a subscription based cloud solution.
Efficient tools
Efficient tools - don’t we all love that? The thing is, like most things in life, you should make some effort to get them:
- You should read a lot of articles and blog posts to discover and compare them.
- You should spend time to learn how to use them.
- You should pay, if they are not free to use.
For example, when I built and trained neural networks using python and numpy, everything seemed complicated. Then I discovered keras - high level machine learning library. It made me 10 times faster and my code was much more readable and stable.
Another problem is, we keep doing the same task again and again without spending any time to automate them. Imagine once you get a project, which requires you to create an image classifier. You spend 2-3 months trying to train the best performing classifier. Then you get a similar image classification project a year later. By that time, you’ve perhaps forgotten half of the things, which you did in your previous image classification project. That’s why, you spend 2 months again to train an image classifier for you new project. Wouldn’t it be nicer if you had a platform, which had already automated repetitive parts of training machine learning models, so that you didn’t have to write code for training the same type of machine learning model every year from scratch? There are some new libraries, which try to address this problem. For example, AutoKeras and Google AutoML, which try to automate neural architecture search and hyperparameter tuning. Another solution is Intelec AI , which provides a subscription based platform to automate training and deployment of machine learning models. You can also deploy and use models, which have already been trained for you.
Summary
Shortage of data science skills is real. The problem can be addressed by training more data scientists and making them as efficient as possible. MOOCs are perfect for training more data scientists at massive scale, while we have new platforms, which make data scientists more efficient by automating repetitive parts of training machine learning models.