Cellular Image Classification for Drug Discovery
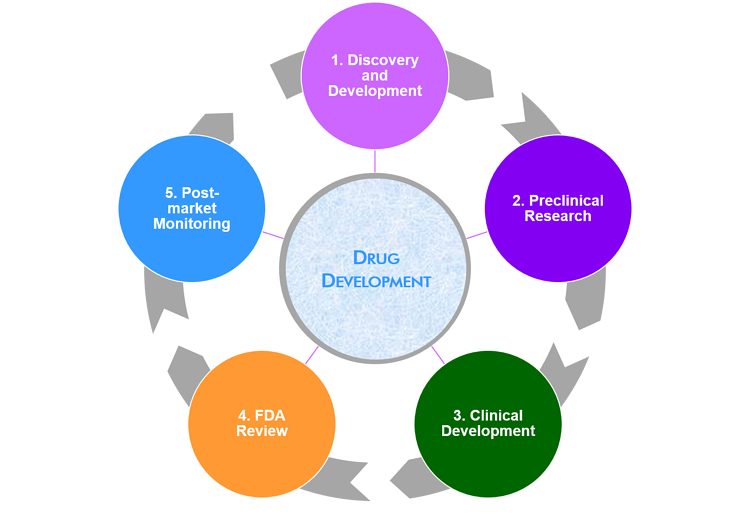
Drug development process is divided into 5 steps in the US:
- Discovery and development
- Preclinical studies
- Clinical development
- FDA Review
- Post-market monitoring
It’s a very lengthy process, which might take 12–15 years and cost around 1 billion dollar. This article explains the basis of drug development very nicely.
Pharmaceutical industry desperately needs to reduce the development time and costs. In this article, I am going to write about how recent advances in deep learning help to improve the early drug discovery process - the 1st step of drug development.
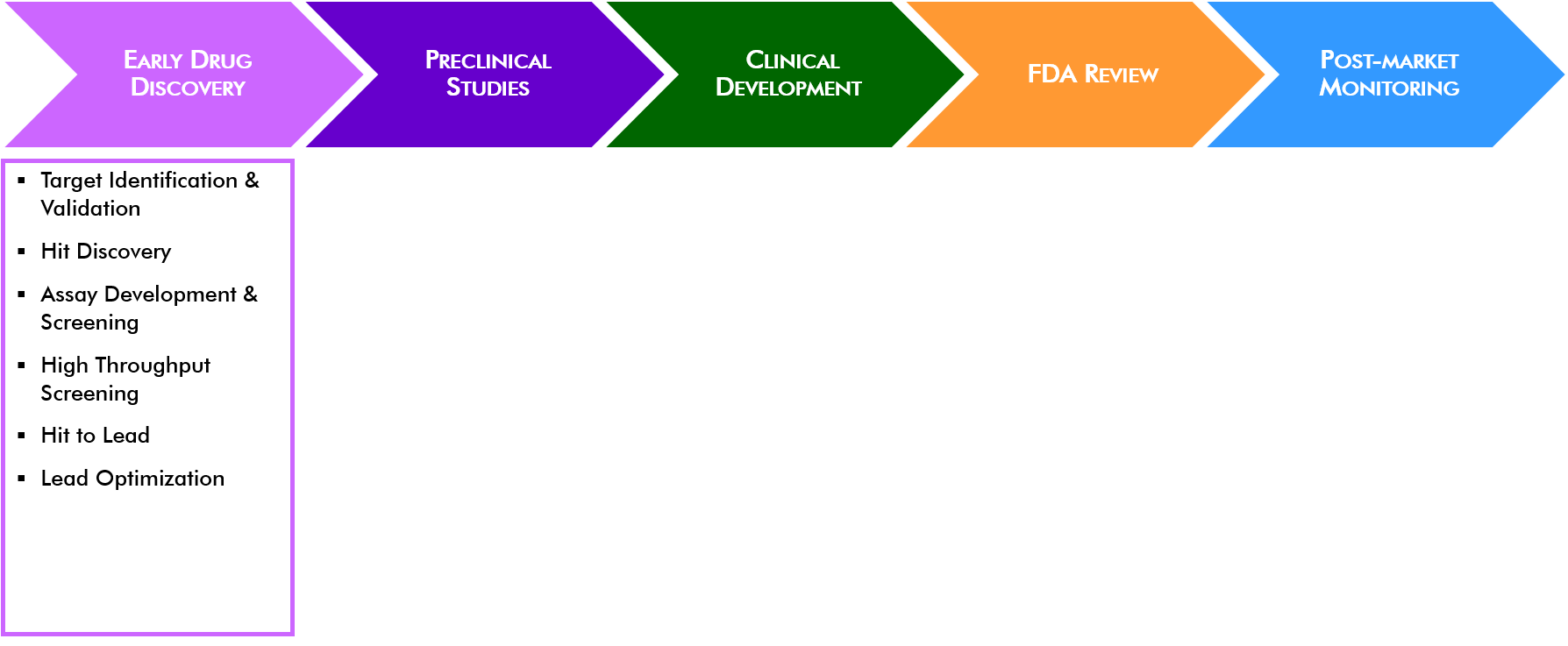
Early drug discovery
Historically, drugs were mostly found by identifying active ingredients from traditional medicines or purely by chance. Today drug discovery involves target identification and validation, hit discovery, high throughput screening, and optimization of hits to reduce potential side effects.
Hits are molecules, which interact with the target in some way. High Throughput Screening (HTS) is one of the powerful ways of discovering hits. With help of robotics, data processing software and sensitive detectors drug discovery teams perform HTS experiments to rapidly conduct thousands of pharmacological, chemical, and genetic tests to identify active compounds, genes, or antibodies that affect target molecules.
Understanding drug-cell interaction
Simply put, candidate drug should at least interact with the target compound. One way of testing this is
- applying a candidate drug on the target cells
- taking images of cells using fluorescent microscopy
- observing how the cells changes after the drug has been applied
One can claim that if the cells undergo changes after drug application, then drug must interact with the cells. However, cells can change also due to other factors like change in room humidity or temperature or due to some unknown factor. This is called experimental noise. To combat this, one needs to repeat the same experiment multiple times and see whether the changes in the cells are consistent throughout the experiments. If there is high consistency, we should be able to guess the applied drug with high accuracy given the images of the cells.
Cellular image classification challenge
Recursion Pharmaceuticals is one of the companies, which does high throughput screening for hit discovery. It released some of its data as a Kaggle challenge.
The dataset contains around 750,000 images of more than 1100 drugs being applied to multiple cell cultures. There are 51 batches of experiments. Each batch has 4 plates, each of which has 308 filled wells. Each well is monitored at two sites while being photographed across 6 frequencies.

Installing machine learning tools
Since we’re going to perform image classification, we need to decide which machine learning tool we would like to use. We chose Intelec AI, because it lets one train and deploy machine learning models just by clicking around on its web interface - easy and straightforward. You can download and install it for free using the following link:
Preparing data
As I mentioned above, each well was photographed using a fluorescent microscope at 6 frequencies. Hence we had 6 images or channels per well at each site.
In order to decrease the data size, we decided to merge them into one image by assigning a color to each channel.
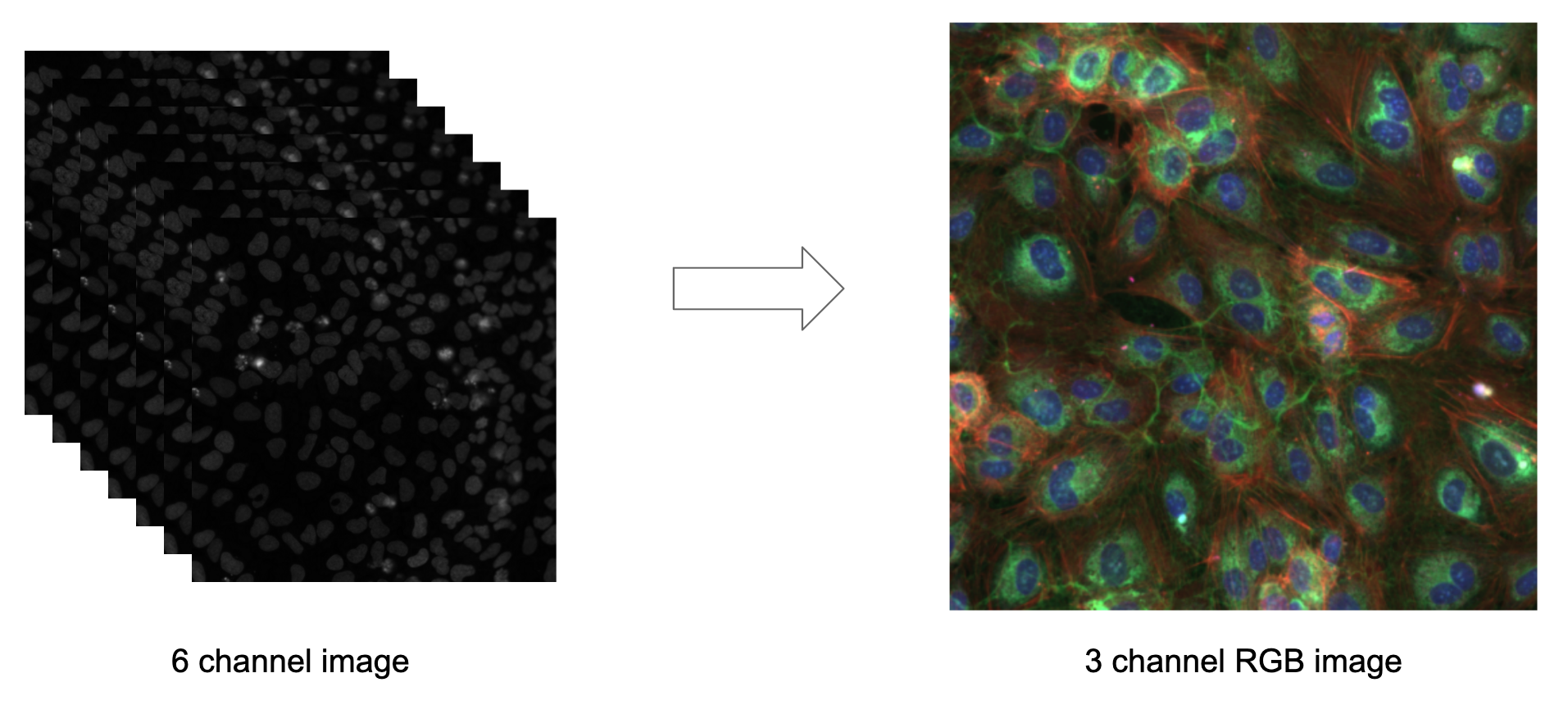
We did it using a handy library from rxrx.ai, which we cloned from here.
Please check out the notebook with all the code here.
Training an image classification model
After so much hussle of cleaning and preparing data the next step was easy. In the next step, we zipped and uploaded the data to Intelec AI. Then we trained a Deep Image Classifier on this data. If you don’t know how to do it, there is a nice tutorial here, which you can follow.
This was our training result:
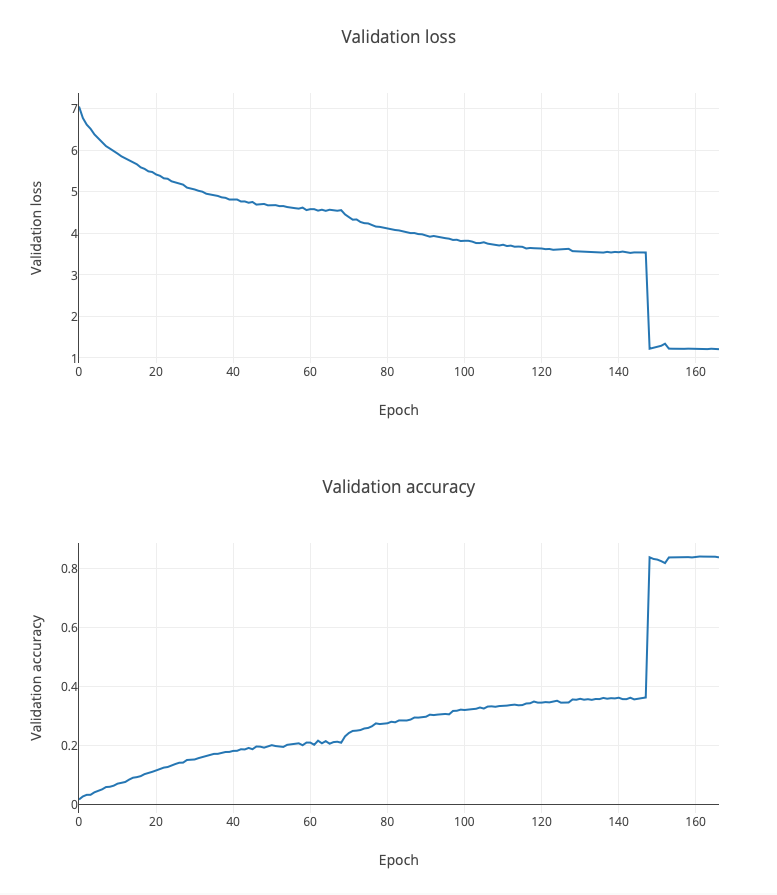
After 100 epoch the accuracy reached 84%. This is a high number considering that we had more than 1100 classes to choose from. I would like to note that the winner of the corresponding competition on Kaggle was able to reach 99% accuracy in the test set. From a pharmacological point of view, this means that all the drugs in the given experiments interacted with the target cells in a consistent way. Otherwise we wouldn’t be able to guess the applied drug, given an image, with such a high accuracy.
Acknowledgements
I would like to thank Recursion Pharmaceuticals for putting out such a nice dataset for others to play with and learn from.
I hope you found the article interesting. Take care, until the next time.